come lavorano i differenti protocolli di rete per una architettura clos Spine and Leaf
15.01 2020 | by massimilianoQuesto documento si prefigge, con un pò di presunzione, di cavalcare le farie fasi che un design datacenter per un […]
https://www.ingegnerianetworking.com/wp-content/uploads/2020/01/arp-garp-header-375.png
Questo documento si prefigge, con un pò di presunzione, di cavalcare le farie fasi che un design datacenter per un ambiente CLOS Spine and Leaf deve attraversare e verificare in modo teorico i differenti protocolli di rete (e sono davvero tanti) che si vanno ad incontrare lungo un progetto.
NOTA: il documento, in modo volontario, segue una linea cisco-oriented
NOTA: il presente documento non vuole essere un progetto esecutivo ma solo una condivisione di aspetti pratici e teorici dei protocolli interessati da un ambiente datacenter
Per prima cosa vediamo il design dalla parte di accesso di un server, sia esso virtuale all’interno di un ESXi host oppure fisico (bare-metal) che si collegano a switch layer 2 che fanno parte di una Fabric Clos.
Dal punto di vista del server, questo non sa quale sia l’architettura al di sopra di esso e pertanto, come la sua connessione richiede, prevede pacchetti di trasmissione “ethernet” che permettono una comunicazione di tipo end-to-end tra endpoint.
Quando un server comunica con un’altro server all’interno della Fabric, facciamo riferimento a traffico di tipo “east-west”; quando il server è in comunicazione con external-domain in genere si fa riferimento a comunicazioni di tipo “north-south”
Si ricorda che ogni server può essere sorgente o destinazione per sepecifici flussi di comunicazione (bidirezionalità di traffico).
Prima di addentrarci al’interno della Fabric, ritengo utile riportare alcune funzionalità (protocolli) che sono sempre presenti nel proseguo di questo documento e sono: DHCP, ARP, RARP
DHCP:
DHCP permette una assegnazione dinamica di indirizzi di tipo IP (internet protocol) dove un nodo di rete (sia server, PC, altro) invia un messaggio di esplorazione (dhcp discovery) eppoi una vera e propria richiesta dhcp al server che per primo abbia risposto al messaggio iniziale (per evitare la prima fase si mantiene su disco gli indirizzi del server DHCP e le risposte del server contattato e grazie a questa informazioni i successivi riavvi del server (boot) saranno più veloci (il dhcp di fatto può essere visto come una estensione del boot)
ARP:
Address Resolution Protocol, come dice il suo nome, la risoluzione degl indirizzi è necessaria a livello di rete fisica locale e non è possibile risolvere un indirizzo se non si appartiene alla stessa rete fisica a cui si riferisce l’indirizzo fisico risolto; qualora siamo in presenza di una inter-rete, cioè di più reti fisiche collegate tra loro attraverso nodi layer 3 (router), allora il software di un host-1 che deve parlare con un host-20 appartenente ad un’altra rete fisica, non può risolvere l’indirizzo dell’host-20, ma può inviare un pacchetto al suo router gateway R1 lasciando a lui il compito di risolvere l’indirizzo di quest’ultimo.
Il router R1 gateway di H1, riceve il pacchetto e decide di inviarlo al router successivo R2 e risolve l’indrizzo del router successivo R2; infine il router R2 a conoscenza del host H20 ne risolve il suo indirizzo e consegna il pacchetto; quindi ARP viene utilizzato da un router per trovare l’indirizzo fisico di un host destinatario quando ne conosce la sua rete di appartenenza per la corretta consegna del pacchetto.
La famiglia TCP/IP prevede nel suo stack il protocollo ARP il quale definisce due tipi di messaggio che sono “richiesta” e “risposta”.
Un messaggio di “richiesta” contiene un indirizzo IP e richiede il corrispondente indirizzo fisico (mac-address ethernet)
Un messaggio di “risposta” contiene sia l’indirizzo IP ricevuto che l’indirizzo fisico tradotto.
RARP:
Reverse Address Resolution Protocol, lavora in modo opposto ad ARP, nel senso che l’host è ha conoscenza del suo indirizzo fisico ed emette una richiesta di conoscenza del suo indirizzo IP
GARP:
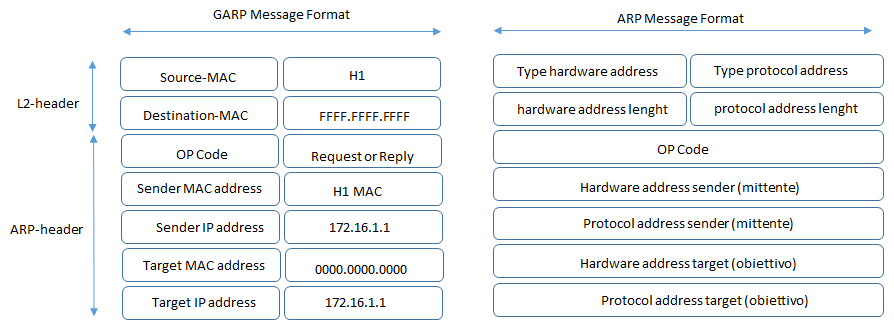
Gratuitous ARP può essere considerato un sistema di notificazione preventiva, aggiornando la tabella arp dei sistemi di rete prima che essi facciano una richiesta arp (nessuna richiesta arp) per essi oppure per motivi di update.
Il pacchetto GARP, quindi presenta le seguenti caratteristiche:
entrambi gli indirizzi IP sia sorgente che destinazione sono dell’host che effettua GARP;
l’indirizzo MAC di destinazione è un indirizzo mac broadcast (ffff.ffff.ffff) e questo significa che il pacchetto può essere inviato a tutte le porte di uno switch
nessun messaggio di risposta è previsto
GARP è principalmente utilizzato per:
aggiornamento della tabella arp a seguito di un cambiamento di un indirizzo fisico oppure IP (failover, NIC diverso, etc..)
aggiornamento della tabella dei mac-address di uno switch
si trasmette un garp request quando una porta di uno switch diventa up per notificare il suo mac/IP agli altri hosts in modo che questi non utilizzano un arp request per il suo discovery
quando esiste un reply a seguito di un gratuitous arp request , significa che il proprio indirizzo IP è in conflitto con altri in rete.
ACCESS LAYER SERVER TO FABRIC:
Dal punto di vista del server, l’architettura che ad esso si presenta è più o meno questa:
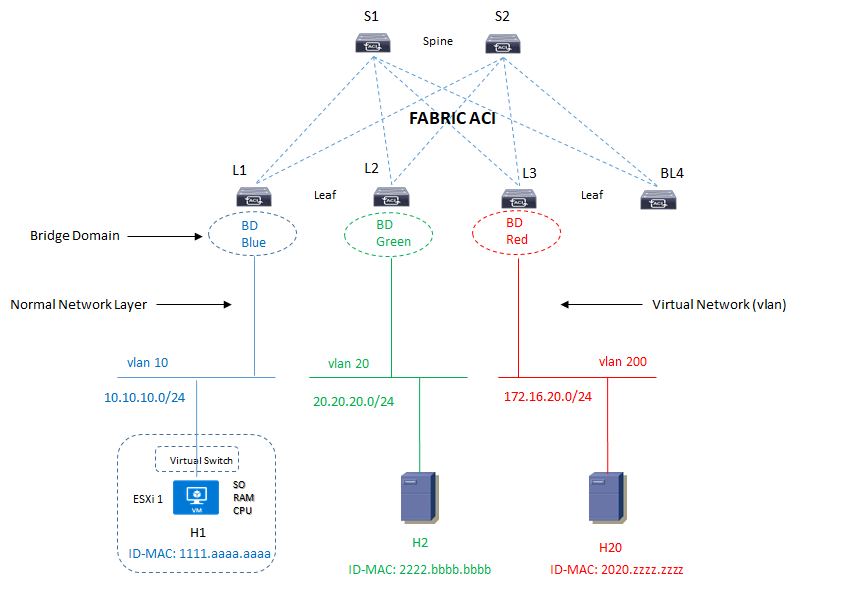
La Fabric in grafica è vista come un unico site di tipo ACI con un proprio control-plane, forwarding-plane e management-plane con APIC server a gestire le policies di rete ed applicative.
ACI Cisco utilizza al concetto di mapping database (conosciuto anche come COOP Council Of Oracle Protocol) per riportare l’architettura con gli indirizzi MAC/IP associati ai rispettivi nodi Leaf e Spine.
Immaginiamo di avere il seguente piano di indirizzamento:
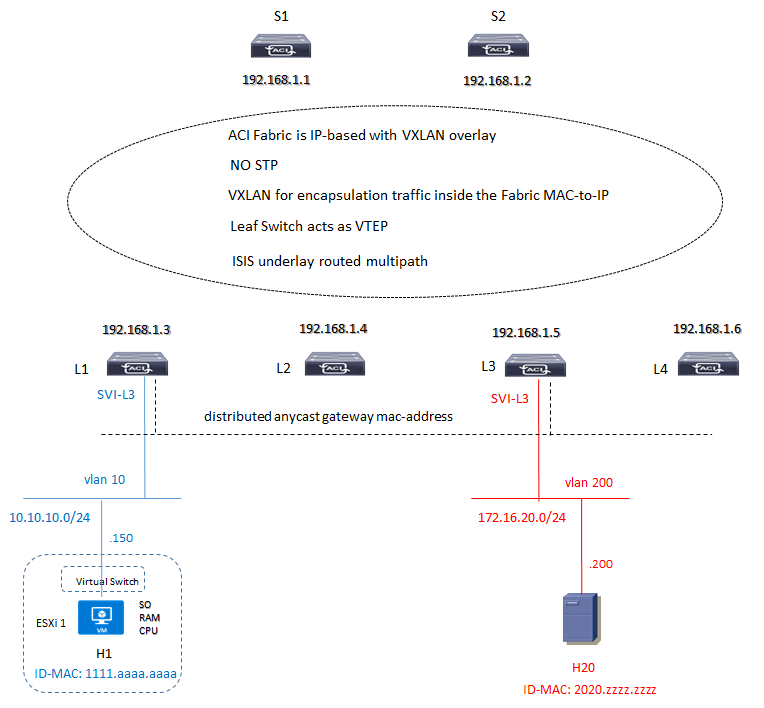
In questo caso abbiamo un underlay protocol ISIS all’interno della Fabric per lo scambio di routing update in modalita ECMP (equal cost multi-path) tra i nodi Spine and Leaf; ad esempio:
Leaf1# show ip route vrf overlay-1 192.168.1.5IP Route Table for VRF "overlay-1"192.168.1.5/32, ubest/mbest: 2/0*via 192.168.1.1, eth1/1.2, [115/3], 6d20h, isis-isis_infra, L1*via 192.168.1.2, eth1/2.2, [115/3], 6d20h, isis-isis_infra, L1
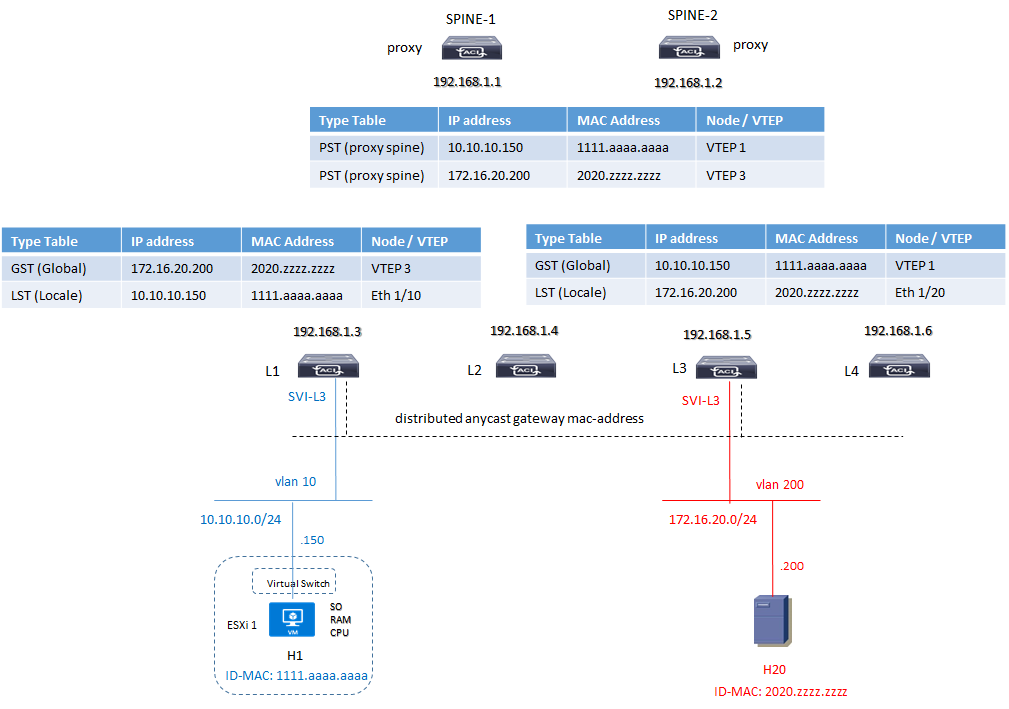
Inoltre sappiamo dal mapping-database che:
il server H1 con MAC-address 1111.aaaa.aaaa ed indirizzo IP 10.10.10.150 è collegato alla porta eth 1/10 del Leaf-1
il server H20 con MAC-address 2020.zzzz.zzzz ed indirizzo IP 172.16.20.200 è collegato alla porta eth 1/20 del Leaf-3
Queste informazioni sono memorizzate all’interno di una tabella chiamata LSP (Local Station Table) dei rispettivi nodi Leaf VTEP:
Leaf1#show endpoint interface ethernet 1/10VLAN/Domain Encap VLAN MAC/IP Address Interface+--------------------------+-------+---------------+----------2051 vlan-10 1111.aaaa.aaaa L eth1/10Tenant-DB-Blue:VRF-overlay-1 vlan-10 10.10.10.150 L eth1/10
Leaf3#show endpoint interface ethernet 1/20VLAN/Domain Encap VLAN MAC/IP Address Interface+------------------------+-----------+------------------+----2052 vlan-200 2020.zzzz.zzzz L eth1/20Tenant-DB-Red:VRF-overlay-1 vlan-200 172.16.20.200 L eth1/20
Una seconda tabella GST (Global Station Table) presente sempre a livello di Leaf ha il compito di mappare gli indirizzi IP degli endpoint remoti con il relativo Leaf VTEP ed inviare queste informazioni a livello Spine i quali utilizzano il protocollo COOP (Council Of Oracle Protocol) con il compito di mappare tutti gli indirizzi MAC/IP address (attraverso una tabella chiamata PST proxy station table) degli endopoint con i relativi VTEP di ingresso permettendo cosi traffico tra endopoint appartenenti a differenti VTEP
Per maggiori informazioni riguardo ACI control-plane and forwarding-plane mapping database vedi: https://www.massimilianosbaraglia.it/switching/datacenter/aci-application-centric-infrastructure/aci-funzionalita/aci-control-plane-and-forwarding-plane-mapping-database
Per vedere gli steps di funzionamento del protocollo overlay control-plane COOP in aci multisite deployment vedi: https://www.massimilianosbaraglia.it/switching/datacenter/aci-application-centric-infrastructure/aci-multisite-deployment/aci-multisite-overlay-control-plane-coop-steps
Spine1#show coop internal info repo ep | egrep -i "mac|real|-"------------------------------------------EP mac : 11:11:aa:aa:aa:aaMAC Tunnel : 192.168.1.3Real IPv4 EP : 10.10.10.150------------------------------------------EP mac : 20:20:zz:zz:zz:zzMAC Tunnel : 192.168.1.5Real IPv4 EP : 172.16.20.200
In caso di dual-Fabric dove ad esempio abbiamo server collocati su differenti sites ma all’interno della stessa subnet oppure su subnet diverse, ACI introduce il concetto di pervasive gateway (anche conosciuto come anycast gateway); ogni Leaf node è il default gateway per gli endpoint a lui collegati.
Un “pervasive gateway capability” permette di avere un virtual MAC address ed un virtual IP address in comune attraverso multiple Fabric ACI; quindi ciascun endpoint oppure un devices appartenente ad uno specifico BD punta come default gateway all’indirizzo pervasive in comune (virtual IP).
Le regole, in ogni caso, prevedono di avere un IP address non virtuale per ogni Bridge Domain della Fabric ACI in modalità “on-top” al virtual IP Address (pervasive).
Questo IP address non virtuale dovrebbe essere nella stessa subnet dell’indirizzo IP virtuale e dovrebbe essere unico per ogni Fabrics ACI; è inoltre richiesto di avere un indirizzo fisico MAC address (custom MAC address in APIC) in ciascun BD ed in ogni Fabric ACI in modalità “stretched”.
Ogni server l’unica cosa che conosce è il proprio indirizzo fisico e l’indirizzo IP ricevuto via DHCP (oppure configurato in modo statico); lo switch a cui è collegato all’interno del proprio bridge domain (vlan-based) costruisce una tabella di mac-address per ciascuna porta in esso contenuta secondo il tradizionale processo di learning di uno switch (Mac Address Table).
Il processo di flooding è attivo qualora lo switch riceva una frame ethernet di tipo broadcast con indirizzo mac FFFF.FFFF.FFFF come destinazione, oppure una frame multicast (con il primo byte contenente un valore dispari)
L’associazione tra il suo indirizzo fisico e la rete a cui appartiene (ARP table) è una informazione che viene mappata dal suo switch Leaf a cui è connesso; gli switch Leaf pertanto oltre a svolgere un livello 2 data-link hanno anche una capabilità layer 3 IP (inter-vlan routing)
Il pacchetto che H1 invia è quindi una frame 802.3 ethernet, i cui field sono:
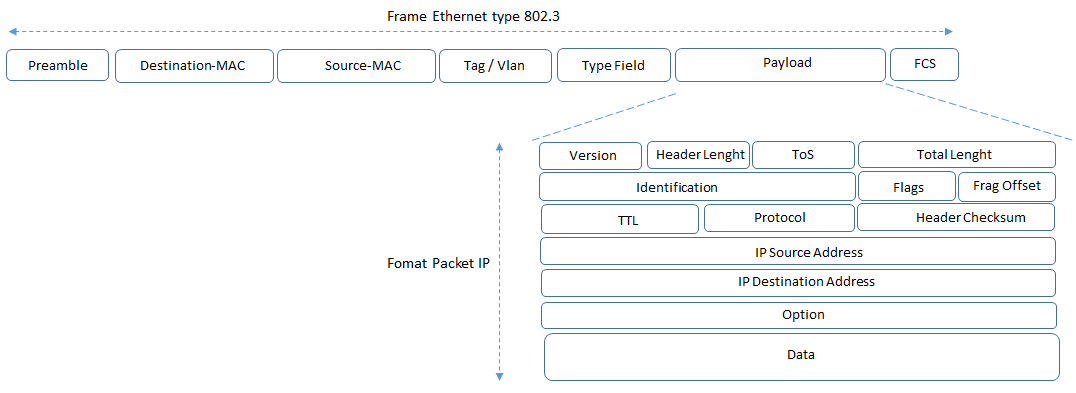
Un bridge-domain è un dominio logico layer 2 in cui è possibile accomodare multiple subnet ed un layer 3 è abilitato attraverso la funzionalità di pervasive gateway capability.
Ogni BD deve essere collegato ad una VRF all’interno della quale ci deve essere almeno una subnet; in questo modo un BD può abbracciare (spanning) attraverso gli switches node ed un MAC-address deve essere unico all’interno del BD.
Ci sono diverse opzioni di forwarding per un pacchetto all’interno di un BD e sono:
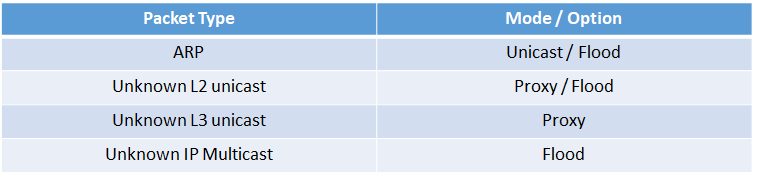
Per maggiori dettagli di BD in ACI vedi: https://www.massimilianosbaraglia.it/switching/datacenter/aci-application-centric-infrastructure/aci-funzionalita/aci-l2-config-parametri-e-steps-di-configurazione
Per maggiori dettagli di L3-interface vedi: https://www.massimilianosbaraglia.it/switching/datacenter/aci-application-centric-infrastructure/aci-funzionalita/aci-l3-config-parametri-e-steps-di-configurazione
Sulla base di quanto appena detto la configurazione della nostra Fabric a livello di accesso e quindi di switch Leaf, dovrebbe essere:
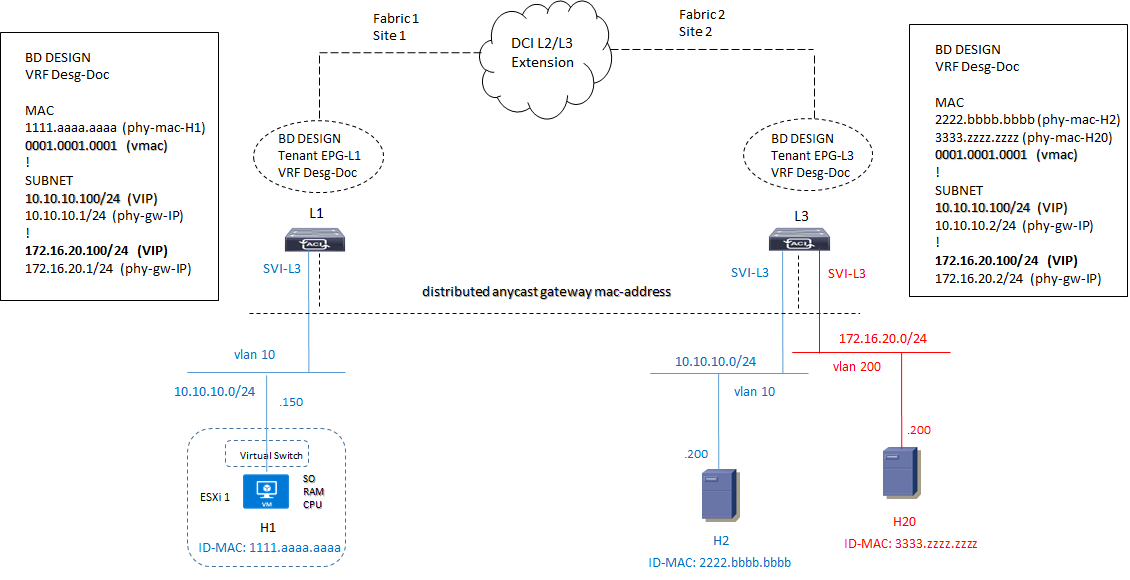
Quindi supponiamo che il server H1 debba comunicare ed inviare delle informazioni al server H20 che si trova su un’altra rete.
1) H1 proverà a fare un ping verso H20 senza successo (ping 172.20.16.100 VIP GW into BD); di conseguenza invierà un pacchetto di tipo ARP-Request al suo next-hop gateway Leaf-1 (L1) in questo formato:
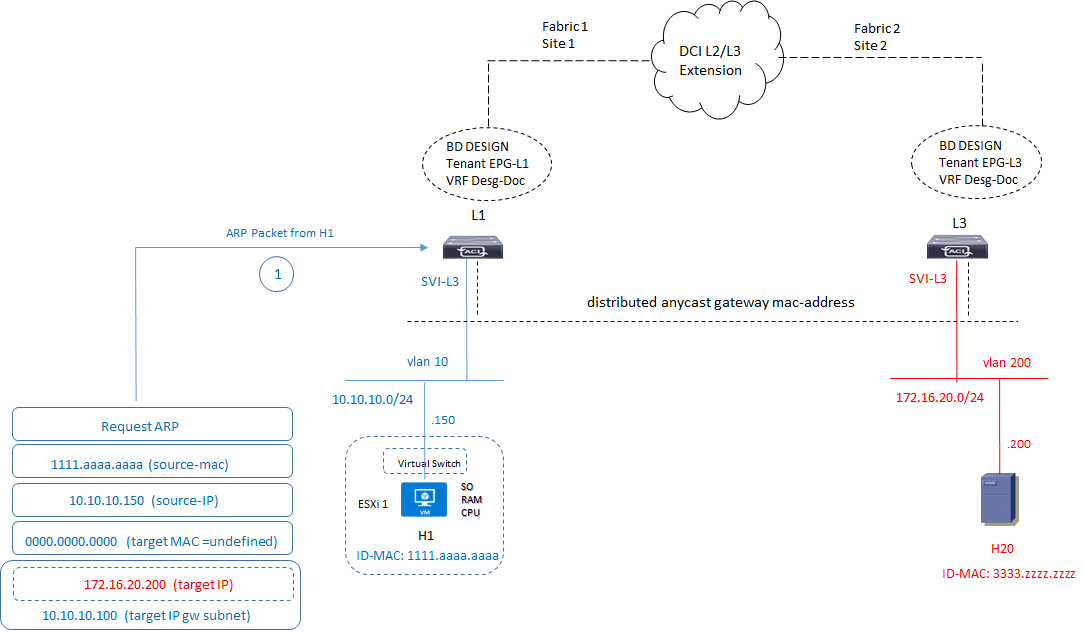
2) Lo switch L1 risponde con un ARP-Reply verso H1 inserendo il suo virtual-MAC address:
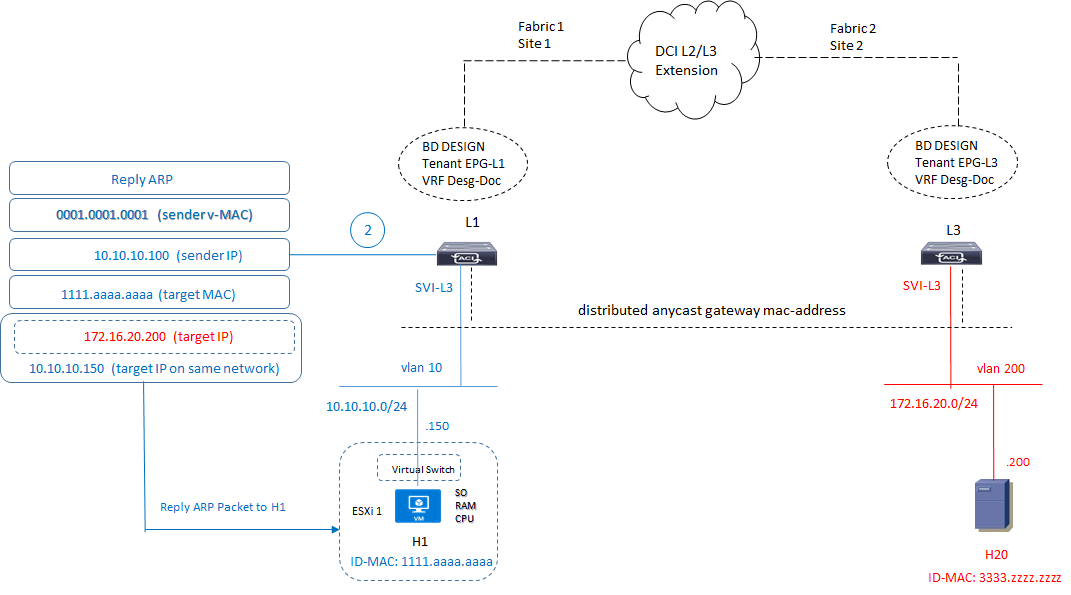
3) ricevuto il reply ARP, il server H1 invia il pacchetto nel seguente formato:
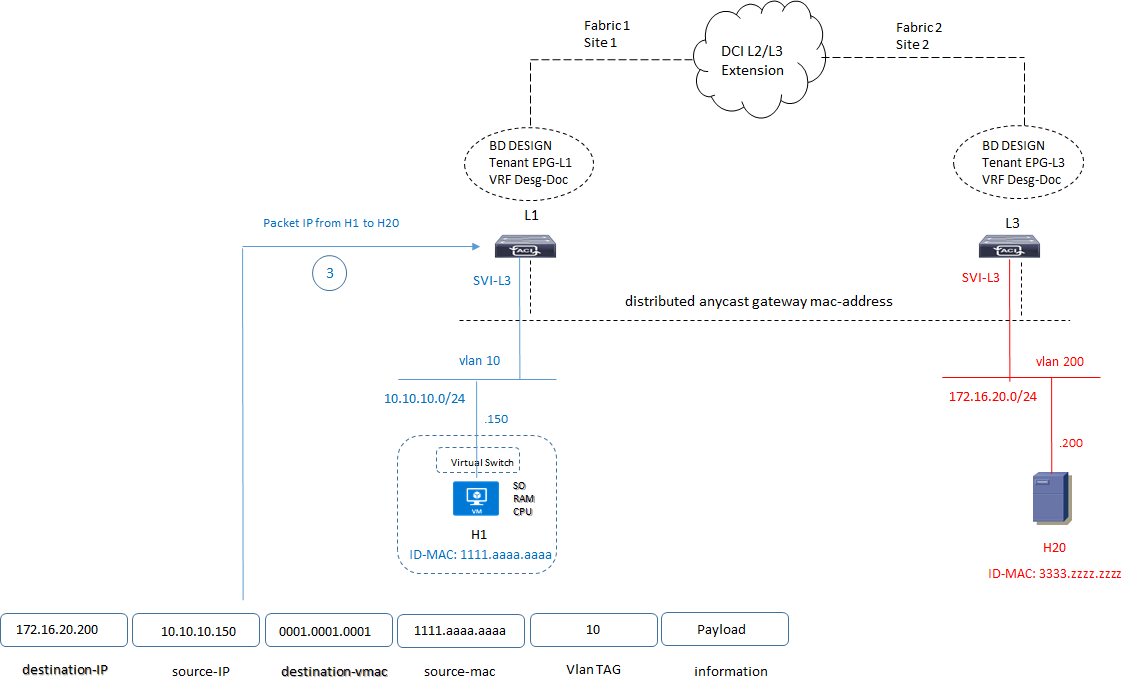
4) Lo switch Leaf L1 ruota il pacchetto verso il livello di Spine Proxy; la funzionalità completa dell’ARP Packets per raggiungere una comunicazione end-to-end tra i due servers (e quindi tra i rispettivi MAC Address sorgente e destinazione) si suggerisce di leggere il link di seguito riportato:
Per maggiori dettagli riguardo il concetto di BD e pervasive gateway capability vedi: https://www.massimilianosbaraglia.it/switching/datacenter/aci-application-centric-infrastructure/aci-funzionalita/aci-concetto-di-bridge-domain-and-pervasive-gateway-capability
5) MP-BGP è utilizzato tra Spine e Leaf per propagare informazioni di external routes all’interno della Fabric ACI
Il piano di controllo è gestito dal protocollo MP-BGP EVPN il quale permette di scambiare informazioni riguardo MAC-Address ed IP address di ciascun endpoint tra Fabric (situazione Multipod oppure MultiSite); il MP-BGP EVPN crea le adiacenze tra gli Spine Node Multi-Site utilizzando un EVPN-RID address e può essere supportato sia l’interior (MP-IBGP) che l’external (MP-EBGP) session, dipendendo dalla tipologia di AS (Autonomous System) utilizzata.
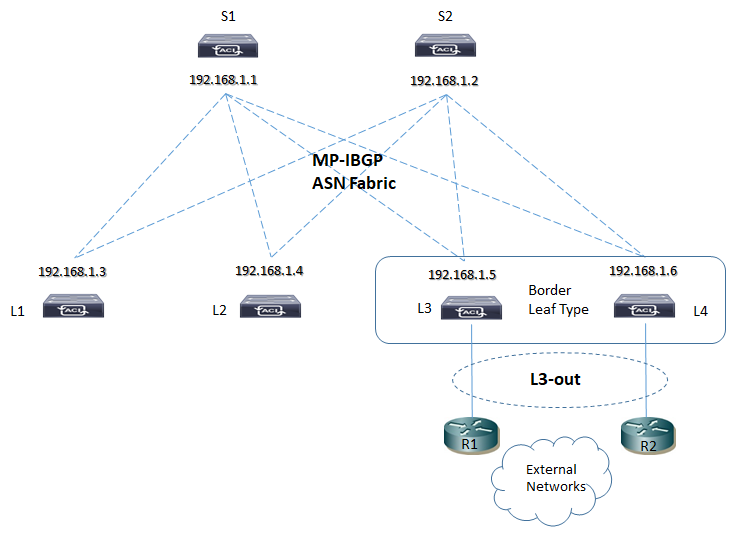
Per aci L3-out steps config exending to external domain vedi: https://www.massimilianosbaraglia.it/switching/datacenter/aci-application-centric-infrastructure/aci-funzionalita/aci-l3-out-extending-to-external-domain-parametri
Per maggiori informazioni riguardo una comunicazione intrasubnet e intersubnet tra differenti Fabric site ed una configurazione esemplificativa di MPBGP EVPN vedi: https://www.massimilianosbaraglia.it/switching/datacenter/vxlan/distributed-anycast-protocol-gateway-and-learning-process-endpoint
CONSIDERAZIONI IN TERMINI DI CONFIGURAZIONE PER IL BGP ALL’INTERNO DI UNA FABRIC DATACENTER:
1) i valori di timer default del BGP potrebbero non andare bene in un ambiente di tipo DC e pertanto si potrebbe pensare ad un tuning quale
- keepalive timers: è il periodo di messaggistica BGP scambiata tra peer (default = 60 sec); portata ad esempio a 3 sec;
- hold timers: è il tempo di “tenuta” della sessione BGP negoziata durante l’apertura della sessione TCP per dichiarare morto il peer (default = 180 sec); portata ad esempio a 9 sec;
- advertisement-interval: è il tempo fissato per gli aggiornamenti di routing (annunci e ritiri di Prefix via update); BGP attende la durata settata dal parametro advertisement-interval tra i vari “sending” successivi di update al peer (di default abbiamo 30 sec per sessioni EBGP e 5 sec per sessioni in IBGP); in un ambiente datacenter questo parametro dovrebbe essere settato a zero in modo tale da portare un tempo di convergenza che è quello del protocollo IGP (OSPF ad esempio)
2) poichè BGP in ipv4 unicast address family in modo di default abilita annunci di prefix, può essere preferito “spegnere” questo comportamento in modo esplicito attraverso il comando:
no bgp default ipv4 unicast
router bgp < as >
bgp router-id < rid >
timers 3 9
no bgp default ipv4 unicast
neighbor < peer > advertisement-interval 0
3) Mutipath Selection: questa considerazione viene fatta nel caso in cui abbiamo un server collegato a due differenti Leaf node (HA) i quali hanno differente numero di AS nella loro topologia EBGP Fabric come ad esempio:
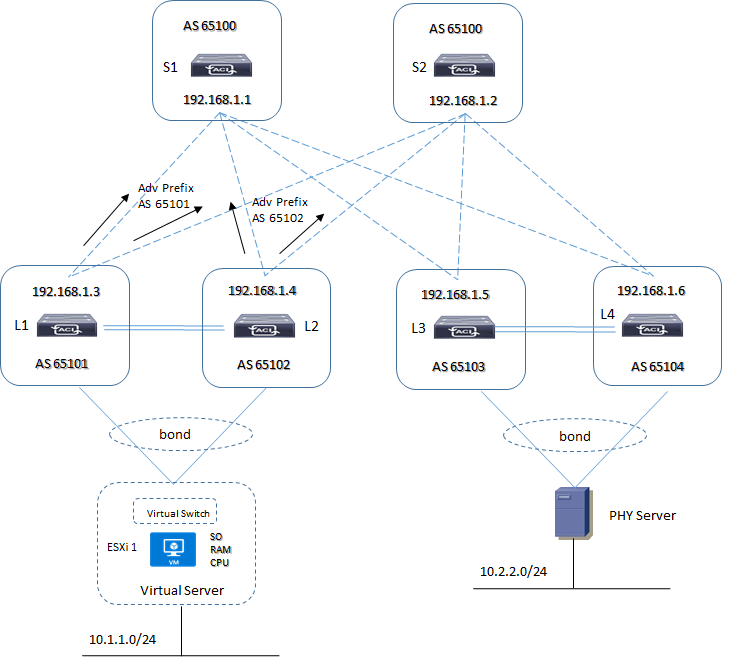
In questo caso i due Leaf L1 ed L2 annunciano via BGP la prefix 10.1.1.0/24 verso gli Spine i quali vedranno la prefix arrivare con due differenti AS e poichè il criterio multipath non è soddisfatto sceglieranno il best-path da uno dei due Leaf.
Il criterio per il multipath dice che due (o più) path sono uguali (equal) se presentano gli stessi parametri in termini di lunghezza (numero di AS-path presenti e nel caso specifico esiste) ma che anche il numero di AS deve essere uguale (stesso ASN ed in questo caso non abbiamo lo stesso ASN)
In un ambiente datacenter dove il criterio dell’equal multipath è importante è possibile “modificare” l’algoritmo di scelta del best-path attraverso un comando: “bestpath as-path multipath-relax” utilizzato per FRR ed altri stack di routing protocol; in questo modo gli Spine possono installare entrambi i path anche se rivevuti da due differenti ASN
router bgp < as >
bgp bestpath as-path multipath-relax
Per maggiori dettagli su come lavora il bgp best-path vedi: https://www.massimilianosbaraglia.it/routing/bgp/bgp-teoria/bgp-best-path-working
Per maggiori dettagli su come lavora add-path vedi: https://www.massimilianosbaraglia.it/routing/bgp/bgp-design-cisco/bgp-router-reflector-functions-with-orr-and-add-path
4) Abilitare sempre l’address-family per ogni neighbor con il comando “activate”; il comando permette a BGP di attivare questa capability nel messaggio OPEN e cosi anche l’advertiment routes per address-family process.
router bgp < as >
address-family ipv4 unicast
neighbor < peer > activate
5) specificare sempre il comando redistribuite sotto una specifica address-family; poichè BGP è un multiprotocol routing process, il comando redistribuite redistribuisce le informazioni di routing solo all’interno di ciascuna address-family dove è presente
router bgp < as >
address-family ipv4 unicast
redistributed connected
6) BGP necessita di configurare in modo esplicito la funzionalità del multipath (a differenza dei protocolli IGP come OSPF) attraverso il comando “maximum-path” all’interno della propria address-family (AFI/SAFI)
router bgp < as >
address-family ipv4 unicast
maximum-path < number_path >
Esempio di Architettura CLOS Spine and Leaf con EBGP ASN (external-BGP ASN)
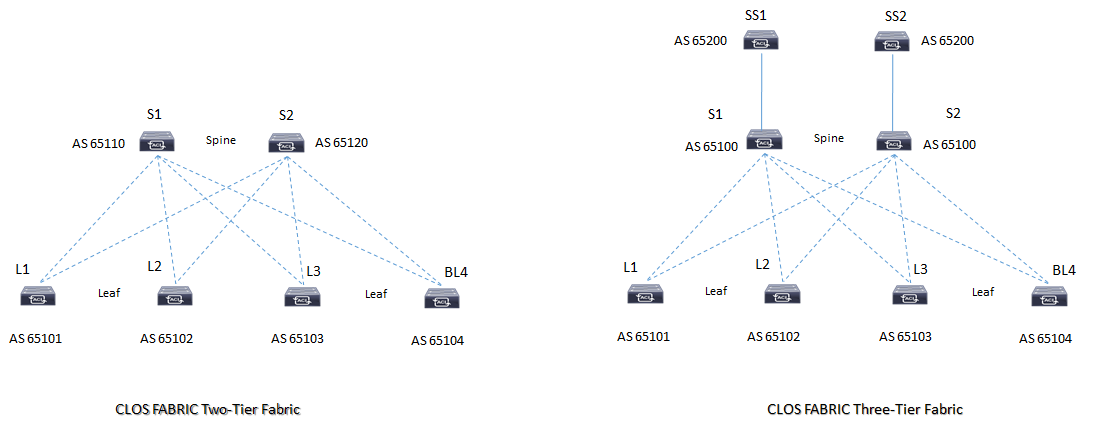
Esempio di Architettura CLOS Spine and Leaf con IBGP:
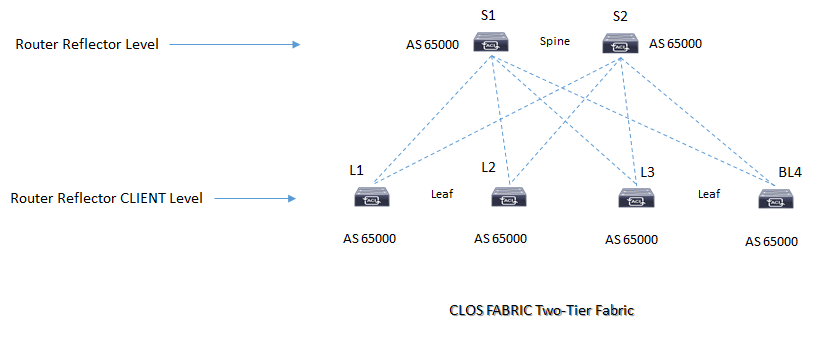
All’interno e per il collegamento verso external domain un DataCenter di tipo CLOS utilizza il MP-BGP per lo scambio di informazioni di differenti address-family ed in particolare la nuova family-address L2VPN EVPN che utilizza i seguenti route-type:
- Route type 1: Ethernet Auto Discovery Route # supporta multihomed endpoint datacenter
- Route type 2: MAC/IP Advertisement Route # advertises reachability di uno specifico MAC di una virtual network (VNI) compreso il suo indirizzo IP
- Route type 3: Inclusive Multicast Ethernet Tag Route # EVPN IR, Peer Discovery; associazione VNI/VTEP dove viene annunciato un VTEP interessato ad una determinata virtual network
- Route type 4: Ethernet Segment Route # assicura che solo un singolo VTEP trasmetta multidestination frames verso multihomed endpoints
- Route type 5: IP Prefix advertisement Route # advertises IP-Prefix quali route summarizzate, VRF associate alla subnet (L3-VNI Route)
- Route type 6: Multicast Group Membership # riporta informazioni riguardo il gruppo multicast di un endpoint collegato ad un VTEP interessato a parteciparvi
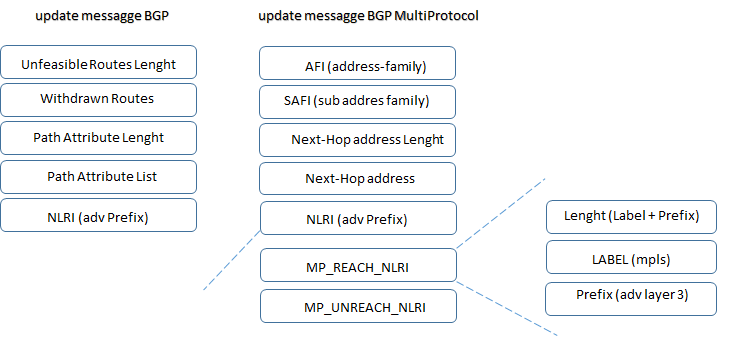
- Si riporta per completezza di informazioni gli header degli update message BGP IPv4 e multiprotocol format:
CONSIDERAZIONI EVPN ALL’INTERNO DI UNA FABRIC DATACENTER:
EVPN è una tecnica che permette queste funzionalità:
- collega un insieme di host (sites) utilizzando un bridge domain layer 2;
- tratta gli indirizzi MAC come address ruotabili e distribuisce queste informazioni via MP-BGP;
- le sessioni L2VPN EVPN tra VTEP possono essere authenticate via MD5 per mitigare problematiche di sicurezza (Rogue VTEP)
- è utilizzato in ambienti data center multi-tenancy con endpoint virtualizzati e supporta l’encapsulation VXLAN;
- le informazioni layer 2 (MAC address) e layer 3 (IP address) imparate localmente da ogni VTEP sono propagate ad altri VTEP permettendo lo scambio e la raggiungibilità di questi attraverso la Fabric; le frame layer 2 sono distribuite tra VTEP con la funzionalità di ARP cache per minimizzare il flooding delle informazioni
- utilizzo di VRF (virtual routing forwarding) ed RD (route distinguisher) per routes/subnets (VNI) (network virtualization); RD per EVPN è definito nella RFC7432 ed è codificato come parte del valore NLRI nel formato MP_REACH_NLRI ed MP_UNREACH_NLRI
- RT (route-target) è un’altro attributo che codifica la virtual network e consente azioni di leaking attraverso l’import e l’export RT

RT Format:
ASN: rappresenta il numero di AS del BGP speaker
A: indica se il parametro RT è in modalità autoconfig oppure è stato configurato manualmente
Type: indica la modalità di encapsulation usata in EVPN (per VXLAN il suo valore = 1; per la VLAN = 0)
Domain-ID: usato per qualificare un dominio amministrativo nel quale una VNI appartiene
Service-ID: contiene il valore VNI (Virtual Network Identifier) (per VXLAN abbiamo 3 byte VNI; per la VLAN abbiamo 12 bits)
GESTIONE DEL TRAFFICO BUM:
Per il traffico di tipo BUM (Broadcast, Unknow-unicast oppure Multicast) il VTEP sorgente incapsula le frame in una VXLAN con VNI multicast address group (includendo ARP request. DHCP request, etc) e tutti i VTEP che ricevono questo multicast frame lo processano; PIM sparse mode e BiDir PIM provvedono a servizi Multicast per VXLAN
Ci sono due differenti modi multicast esistono:
1) il VTEP di ingresso replica la frame ad ogni VTEP di destinazione: questa modalità è conosciuta come “head-end replication”; nessun altro VTEP replica lo stesso pacchetto per evitare loops e duplicati.
Questo modello è efficace quando il numero di VTEP è piccolo oppurequando il traffico di tipo multidestination ha un impatto modesto sull’uso di banda all’interno del datacenter come ad esempio frames ARP request, cluster discovery packets, cluster membership packets
Lavora sicuramente meno bene quando il traffico multicast è davvero intensivo come ad esempio IPTV o traffico multimediale.
2) underlay routed multicast per la consegna di pacchetti a multiple destinazioni VTEP dove il VTEP di ingresso utilizza un indirizzo multicast come destination IP address ed il mcast routing per la trasmissione dei pacchetti; tutti i VTEP compreso i nodi Spine debbono supportare il multicast-routing quale PIM-SM e questo deve sostenere MSDP (Multicast Source Discovery Protocol)
EVPN comunque raccomanda l’utilizzo di PIM-SSM (Source Specific Multicast) in quanto più corretto per il suo impiego
Per il traffico multicast con EVPN è necessario che tutti i VTEP siamo compatibili per supportare il route-type 3 (visto sopra) importante per il trasporto di un attributo BGP conosciuto con il nome di PMSI (Provider Multicast Services Interface) nel quale EVPN suggerisce alcuni valori per la segnalazione di PIM-SSM, PIM-SM, Bidir-PIM e IR (Ingress Replication)
NOTA: l’implementazione del multicast all’interno di un Datacenter prevede una contestualizzazione che solo un progetto LLD di dettaglio può fare scegliere la soluzione da preferire.
EVPN mcast with Ingress Replication Example:
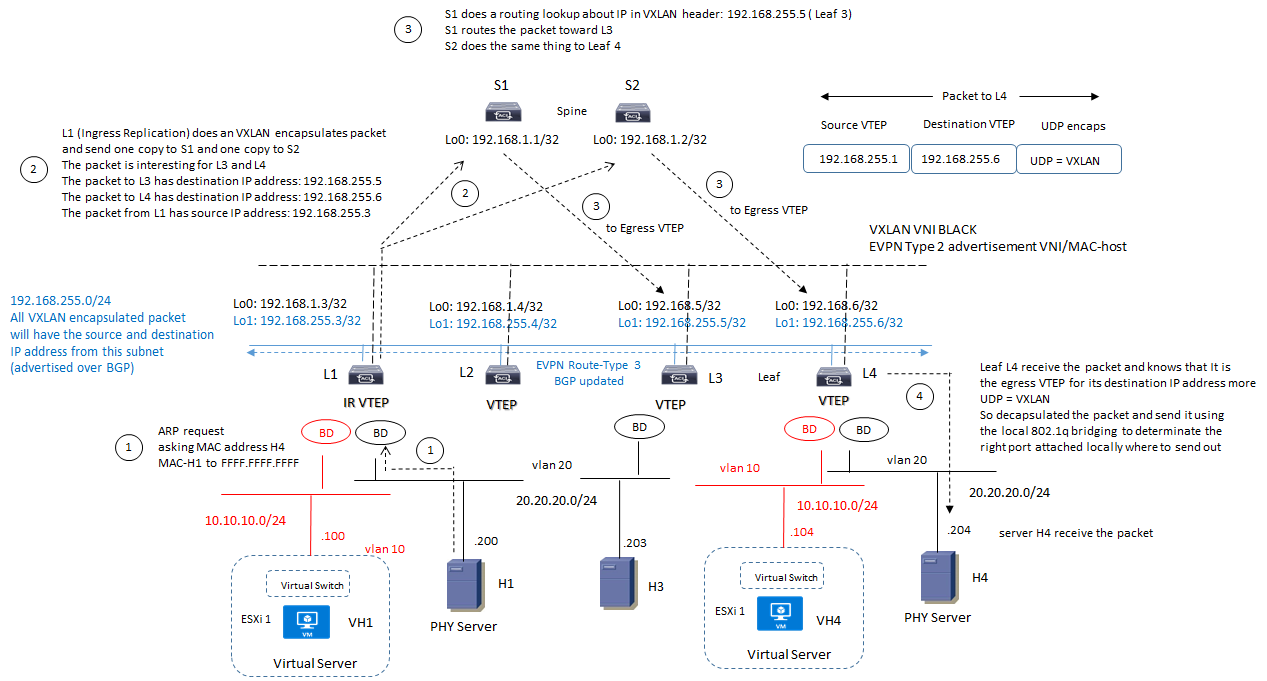
- EVPN utilizza lo split-horizon check per evitare di trasmettere un pacchetto indietro via VXLAN overlay;
- EVPN utilizza RT-3 routes dove ciascun nodo Leaf VTEP può conoscere quale altro VTEP è interessato a partecipare a quella determinata virtual network;
- EVPN utilizza RT-2 routes per trasportare la coppia VNI/MAC: questa informazione dice nel nostro esempio che il MAC-address del server H1 appartenente alla VNI BLACK è raggiungibile via Leaf L1-VTEP; L1 invia questa informazione ai suoi BGP peer S1 ed S2 (Spine Level) ed essi a loro volta inviano questa informazioni ai rispettivi BGP peer (nel nostro esempio L2, L3, L4).
I nodi Leaf ricevono multiple copie (update bgp) ciascuna dai rispettivi Spine e popolano la loro tabella mac forwarding
I nodi Spine non hanno conoscenza del VNI
NOTA: se ad esempio un ARP reply da parte del server H4 arriva prima di aver aggiornato la tabella MAC del Leaf L4, questo verrà inviato come broadcast packet. Se invece arriva dopo che L4 abbia aggiornato la sua tabella MAC basata sui messaggi update BGP provenienti da L1, questo reply viene trasmesso direttamente al nodo L1
EVPN mcast with Routed Multicast:
Questa soluzione è differente dalla precedente e sono indicati due diagrammi di funzionalità mcast routing enable:
Esempio 1:
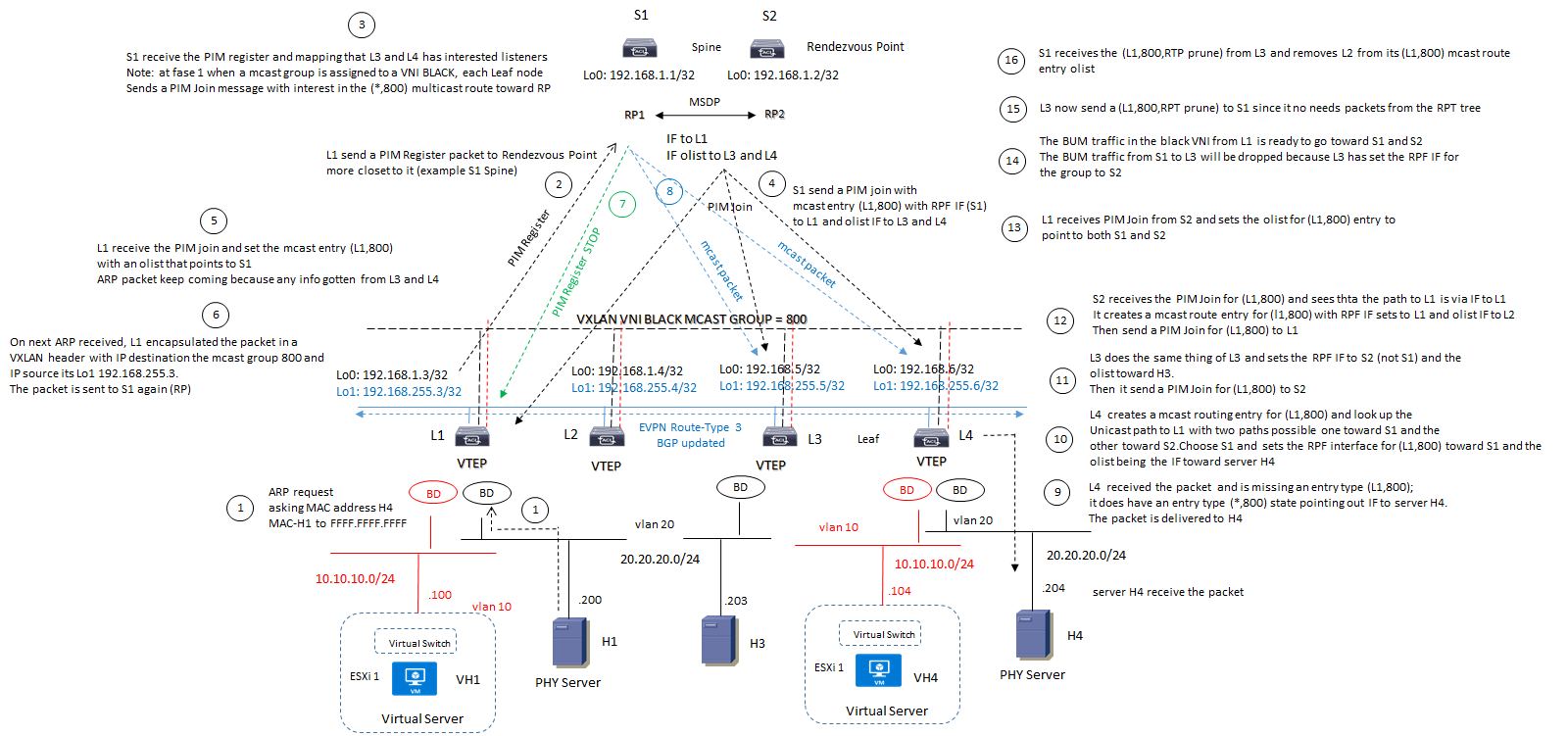
Esempio 2: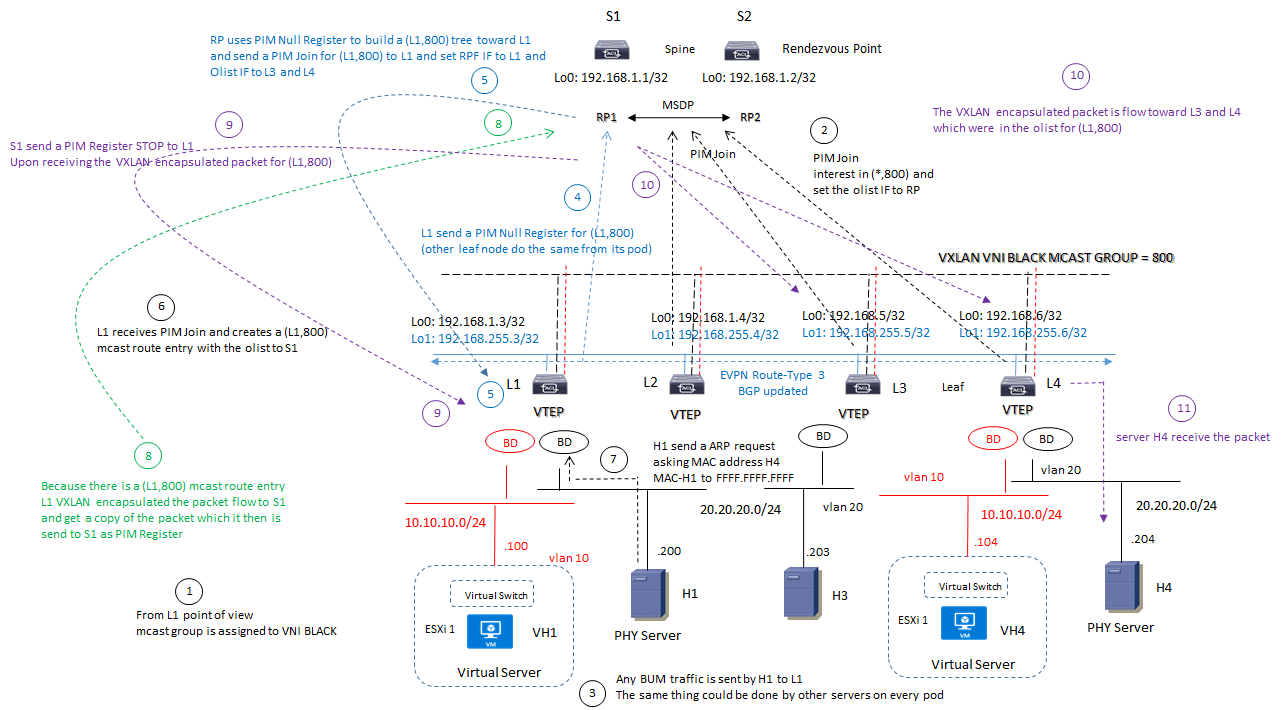
NOTA:
Il ruolo di MSDP è quello di sincronizzare le informazioni tra RP1 ed RP2; di fatto RP è visto come una singola entità logica in HA;
Il ruolo di Rendezvous Point è presente in “routed multicast” con PIM-SM enabled (anche se in questi esempio la collocazione degli RP è basata sugli Spine, nelle applicazioni reali spesso viene assegnata ad altri nodi ad esempio ai Leaf;
Tra Spine e Leaf la rete underlay è sempre routed; i pacchetti sono tra loro ruotati e mai trasmessi in bridging mode; un processo di routing IGP (ad esempio OSPF) è necessario per la costruzione di una routed unicast underlay network;
La parte di bridging 802.1q è presente solo al livello di accesso dei server attraverso le porte CE presenti a livello Leaf;
Tutte le informazioni scambiate in EVPN utilizzano la global VNI (quindi le singole subnet sono anche associate con la global VNI affinchè possa essere stirata (span) tra multipli routers:
Ogni Leaf ha un secondo indirizzo associato con la subnet 192.168.255.0/24 dove tutte le VXLAN encapsulated packets possano avere sorgente e destinazione IP address VTEP da questa stessa subnet; questo indirizzamento deve essere annunciato via BGP;
Ogni nodo Leaf impara attraverso le route-type 3 EVPN (BGP updated) quale altro Leaf è interessato ad unirsi ad una determinata virtual network; questo ad esempio significa che il nodo L1 impara che i nodi L3 ed L4 sono interessati a partecipare all VNI BLACK
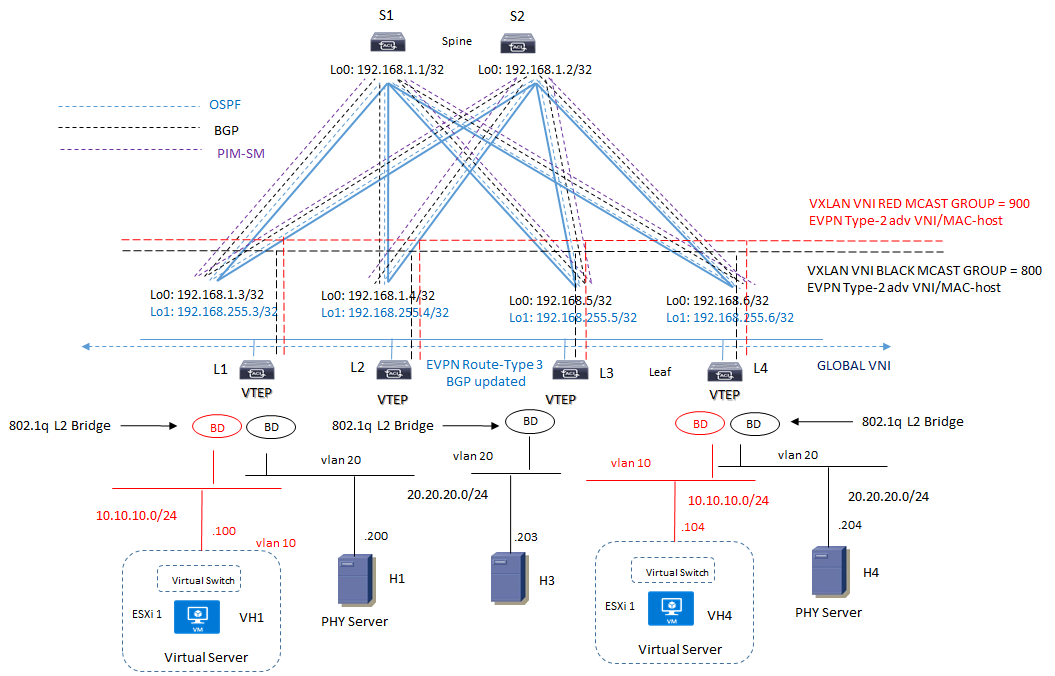
CONSIDERAZIONI ARP/ND SUPPRESSION ALL’INTERNO DI UNA FABRIC DATACENTER:
ARP request e GARP sono pacchetti di tipo BUM in quanto trasmessi verso indirizzi broadcast
ARP suppression permette ad unVTEP di mantenere le informazioni di host reachability in precedenza ottenute da un remote VTEP (cache entry) e comportarsi cosi come un proxy-arp per le successive richieste
NDP è l’equivalente di ARP in IPv6 addresses
ARP/ND suppression utilizzano RT-2 messages per trasportare l’IP address associato con un MAC address per una virtual network
CONSIDERAZIONI MAC MOBILITY ALL’INTERNO DI UNA FABRIC DATACENTER:
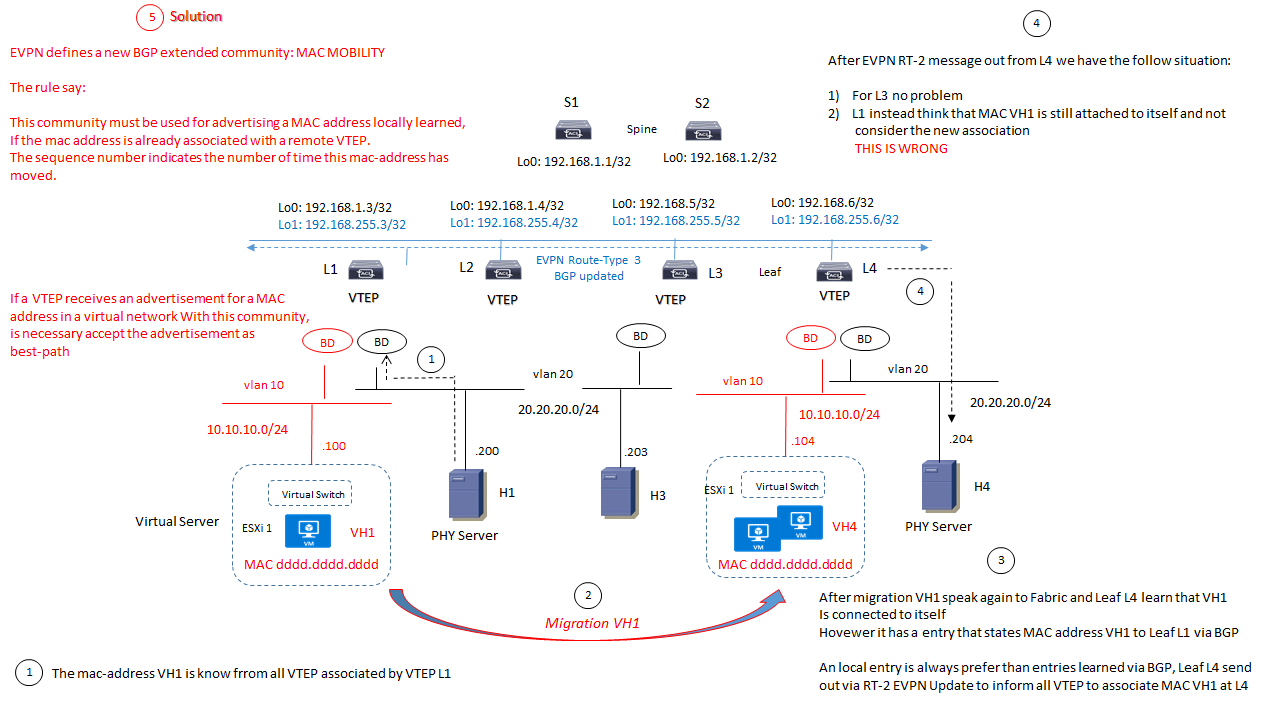

In caso di multipli update ricevuti con lo stesso sequence number da differenti VTEP, vince quello con il VTEP con indirizzo più basso
Static MAC address non sono soggetti a possibili migrazioni/movimenti.
In caso di advertisement di un MAC Address, la route annunciata deve essere taggata con la MAC mobility extended con il bit S settato; quando un VTEP riceve un advertisement MAC address con questo tag presente, deve ignorare qualsiasi cambiamento locale rispetto a quel determinato MAC Address associato alla virtual network
CONSIDERAZIONI EVPN PER SERVER IN DUAL-HOMING LEAF ALL’INTERNO DI UNA FABRIC DATACENTER:
L’architettura a cui mi riferisco è questa:
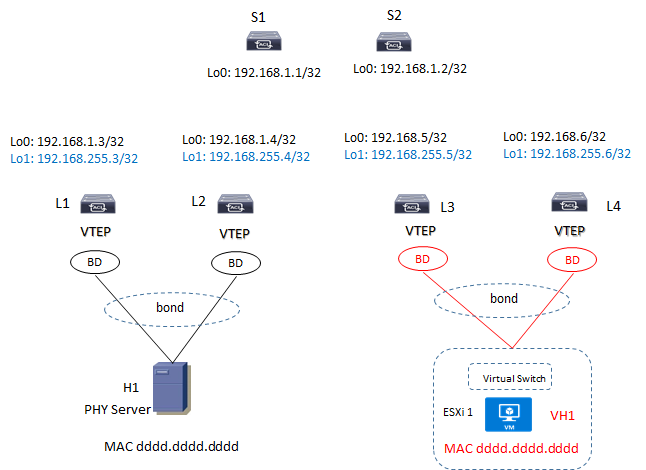
Sulla base di quanto detto sino ad ora un po di domande me le faccio, come ad esempio un collegamento bond viene visto da entrambi i Leaf per i server in dual-homing, come viene gestito il traffico multidestination (BUM), se un server perde la connessione, etc…
Per quanto rigurda il collegamento fisico in dual-homing, il protocollo deve definire una modalità di tipo active-active links (un’altra soluzione è quella del Timing dove però abbiamo un link attivo e l’altro in standby pronto ad essere operativo solo in caso di fault del link “gemello”); i protocolli che possono essere in atto sono MLAG (Multi-Chassis Link Aggregation) ed appunto EVPN.
EVPN supporta nativamente dual-homed devices (RFC7432 e RFC8365), con il trasporto via BGP dei seguenti route-type:
RT-1: informa quale switches Leaf sono collegati verso un devices in comune (questo collegamento è conosciuto come Ethernet Segment); un ethernet segment è definito come un bridged network al quale un VTEP è collegato.
Quando esiste, quindi, un collegamento bond, RT-1 trasporta un identificatico che fa riferimento al devices collegato (un server nella nostra figura di cui sopra) chiamato ESI (Ethernet Segment Identifier); quando un’altro Leaf VTEP riceve questa informazione via RT-1 BGP update, può determinare quale della coppia di Switches è collegato al server.
RT-4 invece è un attributo che elegge uno dei due peer come designated forwarder per il multidestination frames; RT-4 quindi trasporta una informazione che mappa il valore di ESI con il nodo che è sorgente di quel segment ethernet; ogni VTEP alla fine seleziona l’ethernet segment con il più basso IP address VTEP come designated forwarder per una determinata virtual network (in questo caso un IP address in comune non è richiesto)
Un IP address in comune, invece, deve essere previsto tra i due swithes Leaf quando è previsto un bond di collegamento di tipo active-active links
CONSIDERAZIONI VXLAN ALL’INTERNO DI UNA FABRIC DATACENTER:
VXLAN è una tecnica di tunneling (point to multipoint) che permette di creare una rete virtuale layer 2 ti tipo overlay costruita su una infrastruttura underlay layer 3 IP.
All’interno di un DataCenter le VXLAN packets sono associati ad una VRF.
VXLAN utilizza UDP over IP come tecnica di encapsulamento; i VTEP sono gli edge router dei tunnel VXLAN.
Per maggiori dettagli vxlan header vedi: https://www.massimilianosbaraglia.it/switching/datacenter/vxlan/vxlan-overview-and-header
Per maggiori dettagli vxlan evpn vedi: https://www.massimilianosbaraglia.it/switching/datacenter/vxlan/vxlan-evpn-funzionalita-ed-header-format
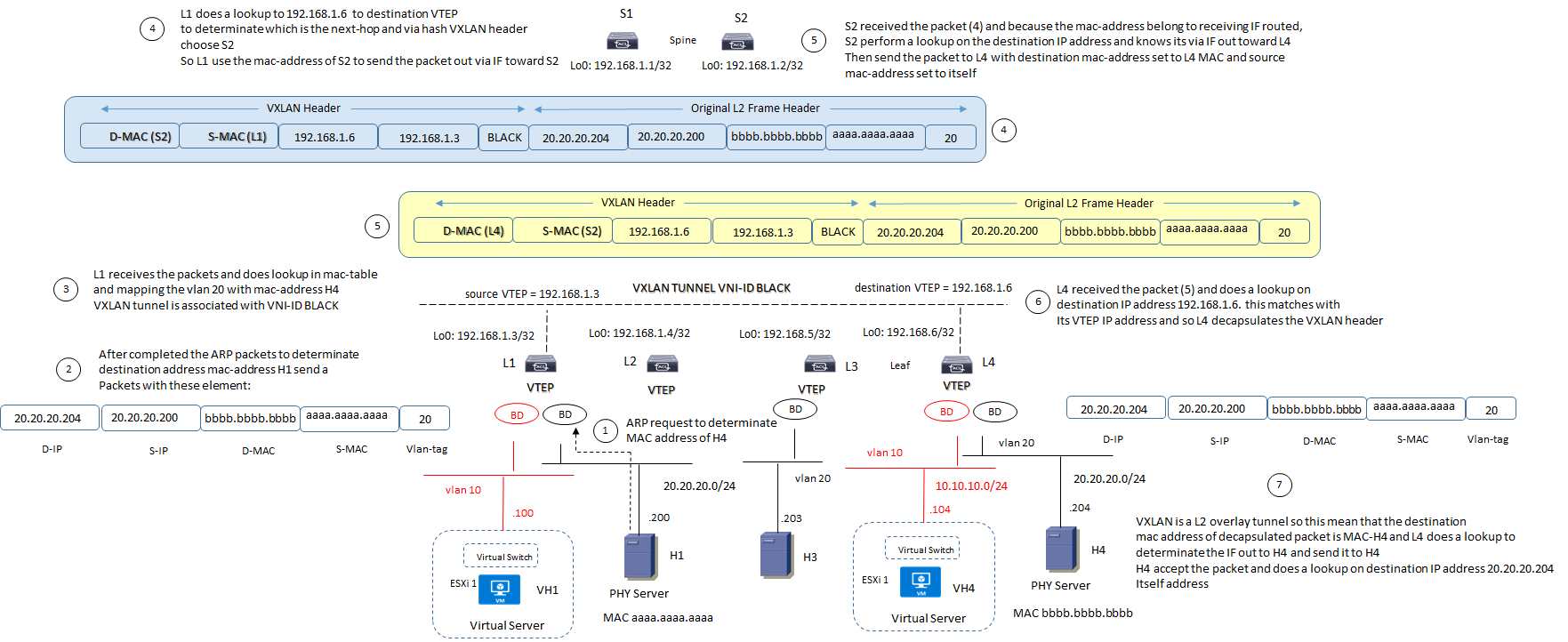
VXLAN BRIDGING MODE:
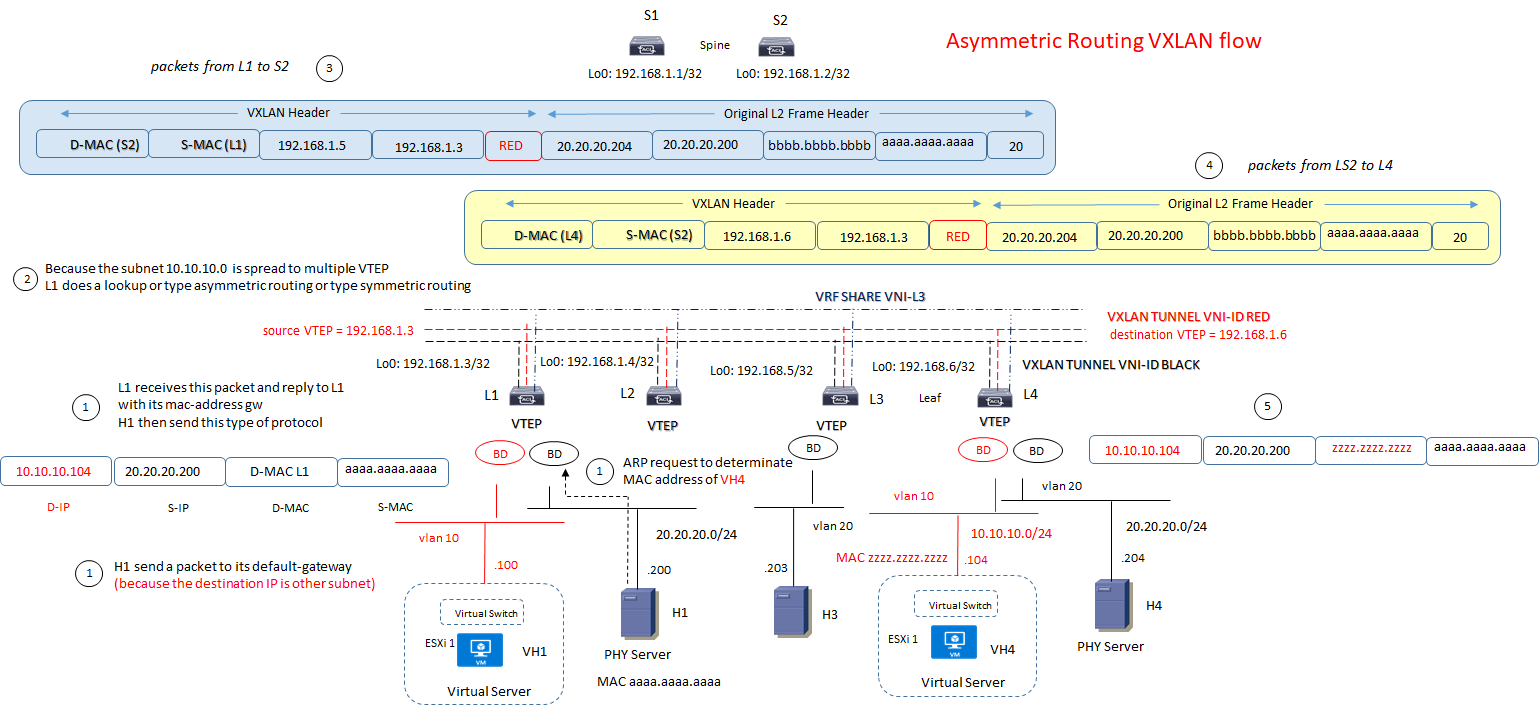
VXLAN ROUTING MODE with Asymmetric flow:
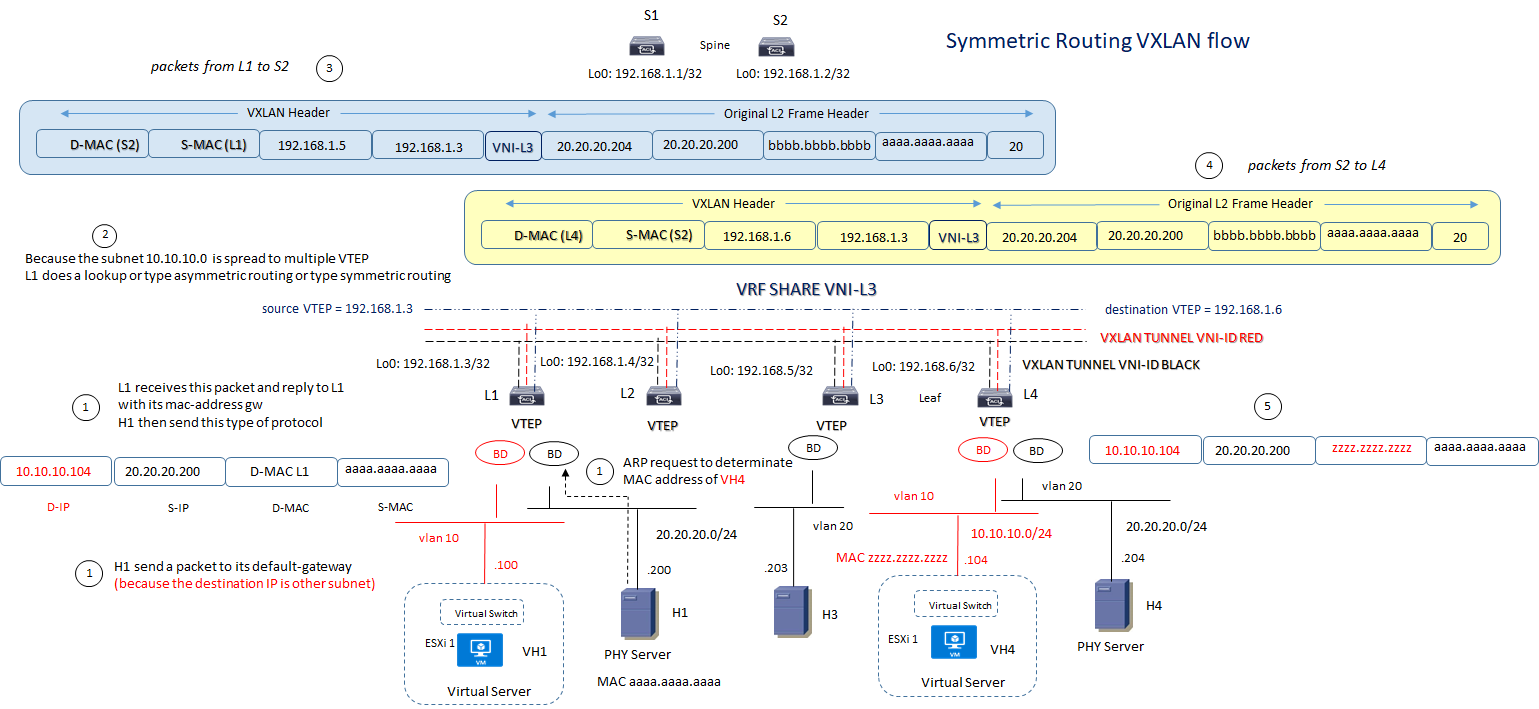
VXLAN ROUTING MODE with Symmetric flow:
Esempio di Configurazione:
Enable Feature config
feature bgp # activate bgp protocol that will be used for L2VPN EVPN address-family
feature vn-segment-VLAN-based # this feature allow you to map a VNI to a VLAN
feature nv overlay # this is VXLAN Feature
feauture nv overlay evpn
Other features need to be activated for your underlay infrastructure like:
feature ospf
feature pim
feature interface-VLAN
VTEP L1 config:
Vlans database, fabric forwarding anycast-gateway-mac and pim multicast configuration parameters
vlan 1,10,20,30
!
fabric forwarding anycast-gateway-mac 0001.0001.0001
!
ip pim rp-address 172.16.1.1 group-list 224.0.0.0/4
ip pim ssm range 232.0.0.0/8
Vlans Black ed associarla ad un segmento VXLAN VNI and L3-VNI intervlan routing
VLAN 100 # vlan 100 is used as Layer 3 VNI to route inter-vlan routing (VRF-SHARE)
name L3-VNI
vn-segment 1000100
!
VLAN 20
name BLACK
vn-segment 2000020
!
VLAN 10 RED
name RED
vn-segment 3000030
EVPN configuration permit the exchange of L2 reachability between VTEPs
evpn
vni 2000020 l2
rd auto # RD is default calculated as VNI:BGP Router ID
route-target import auto # RT is default calculated as BGP AS:VNI
route-target export auto
!
vni 3000030 l2
rd auto
route-target import auto
route-target export auto
Definizione layer 3 VRF per inter-VNI traffic
vrf context SHARE
vni 1000100
rd auto
address-family ipv4 unicast
route-target both auto
route-target both auto evpn
!
interface VLAN 20
description BLACK
vrf member SHARE
ip address 20.20.20.1/24
no shutdown
fabric forwarding mode anycast-gateway
!
interface VLAN 10
description RED
vrf member SHARE
ip address 10.10.10.1/24
no shutdown
fabric forwarding mode anycast-gateway
!
interface VLAN 100 # Layer 3 VNI associated interface vlan does not have an ip address.
vrf member SHARE
no shutdown
Definizione NVE tunnel logical interface where VXLAN packets are encapsulated and decapsulated
interface nve1
no shutdown
source-interface loopback0
host-reachability protocol bgp
member vni 1000100 associate-vrf
member vni 2000020
mcast-group 239.1.1.1
suppress-arp
member vni 3000030
mcast-group 239.1.1.2
suppress-arp
# suppress arp permit to VTEP to cache host-reachability information for remote VTEPs and behave later like a proxy-arp when it receives an ARP request from end host and the information is already in his cache table.
Configurazione physical interface and ospf underlay
interface Ethernet1/2 # ospf with PIM is used as Underlay.
description “to Spine”
mtu 9216
bfd interval 150 min_rx 150 multiplier 3
ip address 10.1.1.2/30
ip ospf network point-to-point
ip router ospf UNDERLAY area 0.0.0.0
ip ospf bfd
ip pim bfd-instance
ip pim sparse-mode
no shutdown
!
interface Ethernet1/10 # Port to Host H1
swithport
switchport mode trunk
switchport trunk allowed vlan 10,20
spanning-tree port type edge trunk
no shut
!
interface loopback01 # Loopback for BGP Peering.
description “Loopback for “BGP”
ip address 192.168.1.3/32
ip router ospf UNDERLAY area 0.0.0.0
ip pim sparse-mode
!
router ospf UNDERLAY
router-id < lo0 >
log-adjacency-changes detail
auto-cost reference-bandwidth 100 Gbps
VTEP L4 config:
Vlans database, fabric forwarding anycast-gateway-mac and pim multicast configuration parameters
vlan 1,10,20,30
!
fabric forwarding anycast-gateway-mac 0001.0001.0001
!
ip pim rp-address 172.16.1.1 group-list 224.0.0.0/4
ip pim ssm range 232.0.0.0/8
Vlans Red ed associarla ad un segmento VXLAN VNI and L3-VNI intervlan routing
VLAN 100 # vlan 100 is used as Layer 3 VNI to route inter-vlan routing
name L3-VNI
vn-segment 1000100
!
VLAN 10
name RED
vn-segment 3000030
!
VLAN 20
name BLACK
vn-segment 2000020
EVPN configuration permit the exchange of L2 reachability between VTEPs
evpn
vni 2000020 l2
rd auto # RD is default calculated as VNI:BGP Router ID
route-target import auto # RT is default calculated as BGP AS:VNI
route-target export auto
!
vni 3000030 l2
rd auto
route-target import auto
route-target export auto
Definizione layer 3 VRF per inter-VNI traffic
vrf context SHARE
vni 1000100
rd auto
address-family ipv4 unicast
route-target both auto
route-target both auto evpn
!
interface VLAN 10
description RED
vrf member SHARE
ip address 10.10.10.1/24
no shutdown
fabric forwarding mode anycast-gateway
!
interface VLAN 20
description BLACK
vrf member SHARE
ip address 20.20.20.1/24
no shutdown
fabric forwarding mode anycast-gateway
!
interface VLAN 100 # Layer 3 VNI associated interface vlan does not have an ip address.
vrf member SHARE
no shutdown
Definizione NVE tunnel logical interface where VXLAN packets are encapsulated and decapsulated
interface nve1
no shutdown
source-interface loopback0
host-reachability protocol bgp
member vni 1000100 associate-vrf
member vni 2000020
mcast-group 239.1.1.1
suppress-arp
member vni 3000030
mcast-group 239.1.1.2
suppress-arp
Nota: la configurazione delle interfacce fisiche viste per il VTEP-4 e l’ospf underlay è medesimo al paragrafo precedente.
CONFIGURATION EVPN Fabric with Router Reflector IBGP
BGP RR config:
router bgp 65000
address-family ipv4 unicast
address-family l2vpn evpn
retain route-target all
template peer IBGP-EVPN
remote-as 65000
update-source loopback0
address-family ipv4 unicast
send-community extended
route-reflector-client
address-family l2vpn evpn
send-community extended
route-reflector-client
neighbor 192.168.1.3
inherit peer IBGP-EVPN
neighbor 192.168.1.4
inherit peer IBGP-EVPN
neighbor 192.168.1.5
inherit peer IBGP-EVPN
neighbor 192.168.1.6
inherit peer IBGP-EVPN
BGP VTEP config:
router bgp 65000
address-family ipv4 unicast
address-family l2vpn evpn
neighbor 192.168.1.1
remote-as 65000
update-source loopback0
address-family ipv4 unicast
address-family l2vpn evpn
send-community extended
neighbor 192.168.1.2
remote-as 65000
update-source loopback0
address-family ipv4 unicast
address-family l2vpn evpn
send-community extended
vrf SHARE
address-family ipv4 unicast
advertise l2vpn evpn